決定木
機械学習および データマイニング |
|---|
 |
問題
|
教師あり学習(分類 • 回帰)
|
クラスタリング
|
次元削減
|
構造化予測
|
異常検知
|
ニューラルネットワーク
|
強化学習
|
理論
|
議論の場
|
決定木(けっていぎ、英: decision tree)は、(リスクマネジメントなどの)決定理論の分野において、
決定を行う為のグラフであり、計画を立案して目標に到達するために用いられる。
決定木は、意志決定を助けることを目的として作られる。
決定木は木構造の特別な形である。
目次
1 概説
2 種類
3 実際の例
4 決定木学習アルゴリズム
5 脚注
6 参考文献
7 関連用語
概説
機械学習の分野においては決定木は予測モデルであり、ある事項に対する観察結果から、その事項の目標値に関する結論を導く。内部節点は変数に対応し、子節点への枝はその変数の取り得る値を示す。
葉(端点)は、根(root)からの経路によって表される変数値に対して、目的変数の予測値を表す。
データから決定木を作る機械学習の手法のことを決定木学習 (英: decision tree learning)、あるいはくだけた言い方では単に決定木と呼ぶ。
決定木による分類モデルはその分類にいたる過程が容易に解釈できるため、決定木はデータマイニングでよく用いられる手法である[1]。その場合、決定木は、葉が分類を表し、枝がその分類に至るまでの特徴の集まりを表すような木構造を示す[2]。
決定木の学習は、元となる集合を属性値テストに基づいて部分集合に分割することにより行うことができる[2]。
この処理は、すべての部分集合に対して再帰的に繰り返される。
繰り返しは、分割が実行不可能となった場合、または、部分集合の個々の要素が各々1つずつの分類となってしまう段階で終了する。[要検証]
決定木は、データの集合を表現したり分類化や法則化することを助ける数学的手法、計算手法であるとも言える。データは以下のような形式のレコードである。
- (x, y) = (x1, x2, x3, …, xk, y)
従属変数 y は、理解し分類や法則化をおこなう対象であり、残りの変数 x1, x2, x3 等はそれらを行う上で参考となる変数である。
種類
決定木には、他に2つの呼び名がある。
- 回帰木 (regression tree)
- 分類に用いられるのではなく、実数値を取る関数の近似に用いられる。(例: 住宅の価格の見積り。患者の入院期間の見積り。)
- 分類木 (classification tree)
y が分類変数の場合。例えば、性別(男あるいは女)、試合の結果(勝ち、負け)
実際の例
ウィキペディアはオンライン百科事典ですが、教科書や注釈付き文書ではありません。 改善やノートページでの議論にご協力ください。(2017年8月) |
決定木を実例で見てみよう。
中野さんは有名なゴルフクラブの経営者。
お客さんの来場状況についてちょっと悩みを抱えている。
お客さんが殺到する日があり、そういう日はクラブの従業員は数が足りない。
そうかと思えばお客さんがまったく来ない日もあり、そんな日は従業員は非常に暇そうだ。
中野さんは、週間天気予報に基づいて、お客さんがいつゴルフクラブにやってくるのかを予想し、
従業員の勤務体制を最適化したいと思っている。
そのためには、もし説明がつくのであれば、人がゴルフをやりたくなる理由を知る必要がある。
そこで2週間の間、中野さんは以下の情報を集めた。
天気(晴れ、曇、雨)、気温(度)、湿度(%),風(強い、弱い)、それにもちろん、彼のゴルフクラブにその日、人が来たかどうか。
結果、以下のような 14 行 5 列のデータを集めることができた。
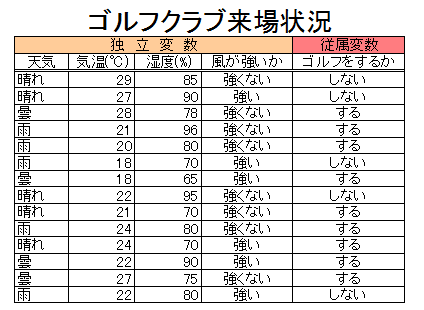
中野さんが抱える問題を解決するために、決定木を作ってみた。

図に示すように、木の形をした閉路を含まない有向グラフである。
一番上の節点は全データを表す。
以下では、この決定木の作り方を述べる。
分類木を自動生成するアルゴリズム(詳細は述べない)があり、それを上の表に示すデータセットに適用すると、従属変数である「ゴルフをするか」を説明する最も良い方法は、変数「天気」を用いることだという結果が得られる。実際、「天気」の値によって表を並び替えると以下の図のようになる。

変数「天気」の分類を用いると、3つのグループが現れる。
晴れの日にゴルフをするグループ、曇の日にゴルフをするグループ、そして驚くべきことに、雨が降っていてもゴルフをするというグループもいることが分かった。
ここでもし、変数「気温」を用いて分類するとどうなるかを考える。
「気温」の値の昇順に表を並び替えると

となるが、ある温度を境にして2グループあるいは3グループに分けるとしても、明確には分けられない。他の変数についても同様である。
「天気」で分類すると、曇の場合に従属変数が "する" であるデータだけのグループが作れることから、
最初に「天気」で分類することは適切な判断と言える。
全データをまずは「天気」で分類することにし、最初の結論としては、天気が曇ならば人は必ずゴルフをし、
雨の日であっても熱狂的な人はゴルフをする! ということが分かる。
さらに、晴れの日のグループを2つのグループに分ける。
お客さんは湿度が70%よりも高い時はゴルフをしたがらないようだ。
最後に、雨の日の場合を2つに分けてみると、風が強い時にはお客さんがゴルフをしに来ることはない、と分かる。
したがって、この分類木によって問題への答えは次のように端的に得られる。
晴れていてじめじめした日や風の強い雨の日にはほとんどゴルフをしに来る人はいないので、
中野さんは従業員のほとんどを休ませるとよい。
それ以外の、沢山の人がゴルフをすると思われる日には、仕事を手伝ってくれる臨時従業員を雇う。
このように決定木は、元の複雑なデータの表現をずっと簡単な構造に変換するのに役に立つ。
決定木学習アルゴリズム
ID3 (Iterative Dichotomiser 3)- C4.5
CART (Classification and Regression Trees)
CHAID (Chi-squared Automatic Interaction Detection)
脚注
^ Segaran 2008, p. 169.
- ^ abMenzies & Hu 2003.
参考文献
- Segaran, T. 『集合知プログラミング』 當山仁健・鴨澤眞夫訳、オライリー・ジャパン、2008年、初版。ISBN 978-4-87311-364-7。
Menzies, T.; Hu, Y. (2003年10月). “Data mining for very busy people”. IEEE Computer: 18–25.
関連用語
- データマイニング
- 木構造 (データ構造)
- ランダムフォレスト
- 二分決定図
- 決定表
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


