ニューラルネットワーク
機械学習および データマイニング |
|---|
 |
問題
|
教師あり学習(分類 • 回帰)
|
クラスタリング
|
次元削減
|
構造化予測
|
異常検知
|
ニューラルネットワーク
|
強化学習
|
理論
|
議論の場
|
ニューラルネットワーク(神経網、英: neural network、略称: NN)は、脳機能に見られるいくつかの特性に類似した数理的モデルである。「マカロックとピッツの形式ニューロン」など研究の源流としては地球生物の神経系の探求であるが、その当初から、それが実際に生物の神経系のシミュレーションであるか否かについては議論があるため人工ニューラルネットワーク(artificial neural network、ANN)などと呼ばれることもある。また生物学と相互の進展により、相違点なども研究されている。
目次
1 概要
2 歴史
3 代表的な人工ニューラルネットワーク
3.1 順伝播型ニューラルネットワーク
3.2 RBFネットワーク
3.3 自己組織化写像
3.4 畳み込みニューラルネットワーク
3.5 再帰型ニューラルネットワーク (リカレントニューラルネット、フィードバックニューラルネット)
3.6 確率的ニューラルネット
3.7 スパイキングニューラルネットワーク
3.8 複素ニューラルネットワーク
3.8.1 利点
4 活性化関数
5 学習
6 実装例
7 脚注
8 参考文献
9 関連項目
10 外部リンク
概要
ニューラルネットワークはシナプスの結合によりネットワークを形成した人工ニューロン(ノード)が、学習によってシナプスの結合強度を変化させ、問題解決能力を持つようなモデル全般を指す。狭義には誤差逆伝播法を用いた多層パーセプトロンを指す場合もあるが、これは誤った用法である。一般的なニューラルネットワークでの人工ニューロンは生体のニューロンの動作を極めて簡易化したものを利用する。
ニューラルネットワークは、教師信号(正解)の入力によって問題に最適化されていく教師あり学習と、教師信号を必要としない教師なし学習に分けられることがあるが、本質的には教師なし学習と教師あり学習は等価である。三層以上のニューラルネットワークは可微分で連続な任意関数を近似できることが証明されている。
画像や統計など多次元量のデータで線形分離不可能な問題に対して、比較的小さい計算量で良好な解を得られることが多い。
現在では、画像認識、市場における顧客データに基づく購入物の類推などとして応用されている(パターン認識、データマイニング)。
歴史
- 1943年、ウォーレン・マカロックとウォルター・ピッツが形式ニューロンを発表した。
- 1958年、フランク・ローゼンブラットがパーセプトロンを発表した。
- 1969年、マービン・ミンスキーとシーモア・パパートが著書『パーセプトロン』の中で、単純パーセプトロンは線形分離不可能なパターンを識別できない事を示した。
- 1979年、福島邦彦がネオコグニトロンを発表し、文字認識に使用し、後にこれが畳み込みニューラルネットワークへと発展する。
- 1982年、ジョン・ホップフィールドによってホップフィールド・ネットワーク(再帰型ニューラルネットワーク)が提案された。
- 1985年、ジェフリー・ヒントンらによりボルツマンマシンが提案された。
- 1986年、デビッド・ラメルハートらにより誤差逆伝播法(バックプロパゲーション)が提案(再発見)された。
- 1988年、畳み込みニューラルネットワークを Homma Toshiteru ら音素の認識に[1]、1989年に Yann LeCun らが文字の認識に使用した[2][3]。LeCunらの多層の畳み込みニューラルネットワークは後にディープラーニングの一種に分類されることになる。
- 1995年 甘利俊一が「神経情報処理の基礎理論の研究」で日本学士員賞を受賞
- 2006年、ジェフリー・ヒントンらによりオートエンコーダ[4]およびディープ・ビリーフ・ネットワーク[5]が提案され、これが、ディープラーニングへと発展した。
代表的な人工ニューラルネットワーク
順伝播型ニューラルネットワーク
順伝播型ニューラルネットワーク(フィードフォワードニューラルネットワーク、略称: FFNN)は、最初に考案された単純な構造の人工ニューラルネットワークモデルである。ネットワークにループする結合を持たず、入力ノード→中間ノード→出力ノードというように単一方向へのみ信号が伝播するものを指す。
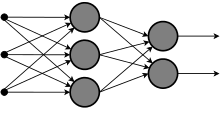
多層パーセプトロンの模式図
- 単純パーセプトロン
- 多層パーセプトロン
教師信号によるニューラルネットワークの学習は心理学者ドナルド・ヘッブが1949年に提唱したシナプス可塑性についての法則、「ヘッブの法則」に基づく。神経細胞間のネットワークの繋がりが太くなり、その結果、特定の細胞への情報伝達経路が作られる(情報が流れやすくなる)、これを学習とする。パーセプトロンは学習の結果、集合を超平面により分割する。この学習は有限回の試行で収束することがマービン・ミンスキーによって1969年に証明された。
1986年にデビッド・ラメルハートらにより誤差逆伝播法(バックプロパゲーション)が提案され、多層パーセプトロンの学習モデルとして使用されている。バックプロパゲーションは主に中間層が1層の時に使われ、中間層が2層以上ある時は深層学習と呼ばれ、入力に近い側の層をオートエンコーダで学習してから積み上げていく方法などが提案されている。
各層を Xi{displaystyle X_{i}} と置くと、下記漸化式で表現される。3層の場合は、X1{displaystyle X_{1}} が入力層、X2{displaystyle X_{2}} が中間層、X3{displaystyle X_{3}} が出力層。




- Xi+1=f(AiXi+Bi){displaystyle X_{i+1}=f(A_{i}X_{i}+B_{i})}

Ai{displaystyle A_{i}} と Bi{displaystyle B_{i}} はパラメータ。Ai{displaystyle A_{i}} は行列、Bi{displaystyle B_{i}} と Xi{displaystyle X_{i}} は縦ベクトル。A{displaystyle A} を重みパラメータ、B{displaystyle B} をバイアスパラメータと呼ぶ。f{displaystyle f} は活性化関数と呼び、単純パーセプトロンでは使われていなかった、つまり、f(x)=x{displaystyle f(x)=x}であったが、すると線形になってしまうので、現在は何らかの非線形関数を使う。微分可能な単調関数を使うことが一般的。最もよく使われるのはシグモイド関数の f(x)=1/(1+e−x){displaystyle f(x)=1/(1+e^{-x})}。







学習は誤差を最小化する最適化問題を解く。最適化問題の解法はバックプロパゲーションを使うのが一般的。誤差は二乗和誤差を使うのが一般的。汎化能力を高めるために、誤差に正則化項を加算することが多い。2次の正則化項を追加する場合、誤差に λ(∑i,jaij2+∑ibi2){displaystyle lambda (sum _{i,j}a_{ij}^{2}+sum _{i}b_{i}^{2})} を加算する。a,b{displaystyle a,b} は A,B{displaystyle A,B} の要素。λ{displaystyle lambda } は実数のパラメータ。




RBFネットワーク
誤差逆伝播法に用いられる活性化関数に放射基底関数を用いたニューラルネットワーク
- RBFネットワーク
一般回帰ニューラルネットワーク(GRNN、General Regression Neural Network)- 正規化したRBFネットワーク
自己組織化写像
自己組織化写像はコホネンが1982年に提案した教師なし学習モデルであり、多次元データのクラスタリング、可視化などに用いられる。自己組織化マップ、コホネンマップとも呼ばれる。
- 自己組織化写像
- 学習ベクトル量子化
畳み込みニューラルネットワーク
畳み込みニューラルネットワークとは層間が全結合ではない順伝播型ニューラルネットワークのこと。
再帰型ニューラルネットワーク (リカレントニューラルネット、フィードバックニューラルネット)
フィードフォワードニューラルネットと違い、双方向に信号が伝播するモデル。すべてのノードが他の全てのノードと結合を持っている場合、全結合リカレントニューラルネットと呼ぶ。
- ホップフィールド・ネットワーク
確率的ニューラルネット
乱数による確率的な動作を導入した人工ニューラルネットワークモデル。モンテカルロ法のような統計的標本抽出手法と考えることができる。
- ボルツマンマシン
- ベイジアンネットワーク
スパイキングニューラルネットワーク
ニューラルネットワークをより生物学的な脳の働きに近づけるため、活動電位(スパイク)を重視して作られた人工ニューラルネットワークモデル。スパイクが発生するタイミングを情報と考える。ディープラーニングよりも扱える問題の範囲が広い次世代技術と言われている。ニューラルネットワークの処理は逐次処理のノイマン型コンピュータでは処理効率が低く、活動電位まで模倣する場合には処理効率がさらに低下するため、実用する際には専用プロセッサとして実装される場合が多い。
2015年現在、スパイキングNN処理ユニットを積んだコンシューマー向けのチップとしては、QualcommのSnapdragon 820が登場する予定となっている[6][7]。
複素ニューラルネットワーク
入出力信号やパラメータ(重み、閾値)が複素数値であるようなニューラルネットワークで活性化関数は必然的に複素関数になる[8]。
利点
- 情報の表現
- 入力信号と出力信号が複素数(2次元)であるため、複素数で表現された信号はもとより、2次元情報を自然に表現可能[8]。また特に波動情報(複素振幅)を扱うのに適した汎化能力(回転と拡大縮小)を持ち、エレクトロニクスや量子計算の分野に好適である。四元数ニューラルネットワークは3次元の回転の扱いに優れるなど、高次複素数ニューラルネットワークの利用も進む。
- 学習特性
- 階層型の複素ニューラルネットワークの学習速度は、実ニューラルネットワークに比べて2〜3倍速く、しかも必要とするパラメータ(重みと閾値)の総数が約半分で済む[9][8]。学習結果は波動情報(複素振幅)を表現することに整合する汎化特性を示す[10]。
活性化関数
ニューラルネットワークにおいて、各人工神経は線形変換を施した後、非線形関数を通すが、これを活性化関数という。様々な種類があり、詳細は活性化関数を参照。
学習
ニューラルネットワークの学習は、最適化問題として定式化できる。
現在最も広く用いられる手法は、勾配法の一種である勾配降下法を連鎖律と共に用いるバックプロパゲーションである。
勾配法によらない学習法 (gradient-free method) は歴史的にも多く用いられており、現在でも研究が進んでいる[1]。
実装例
ここでは、3層フィードフォワードニューラルネットワークで回帰を実装する。x=[−1,1]{displaystyle x=[-1,1]} において、y=2x2−1{displaystyle y=2x^{2}-1} を学習する。活性化関数は ReLU を使用。学習は、確率的勾配降下法でバックプロパゲーションを行う。
![x = [-1, 1]](https://wikimedia.org/api/rest_v1/media/math/render/svg/e126e41300189a8baa1a89169dbe189feeb7e214)

3層フィードフォワードニューラルネットワークのモデルの数式は以下の通り。X が入力、Y が出力、T が訓練データで全て数式では縦ベクトル。ψ{displaystyle psi } は活性化関数。W1,W2,B1,B2{displaystyle W_{1},W_{2},B_{1},B_{2}} が学習対象。B1,B2{displaystyle B_{1},B_{2}} はバイアス項。



- Y=W2ψ(W1X+B1)+B2{displaystyle Y=W_{2}psi (W_{1}X+B_{1})+B_{2}}

誤差関数は以下の通り。誤差関数は出力と訓練データの間の二乗和誤差を使用。
- E=12‖Y−T‖2{displaystyle E={frac {1}{2}}|Y-T|^{2}}

誤差関数 E{displaystyle E} をパラメータで偏微分した数式は以下の通り。肩についてる T は転置行列。∘{displaystyle circ } はアダマール積。


- ∂E∂W1=(((Y−T)TW2)T∘ψ′(W1X+B1))XT∂E∂B1=((Y−T)TW2)T∘ψ′(W1X+B1)∂E∂W2=(Y−T)ψ(W1X+B1)T∂E∂B2=Y−T{displaystyle {begin{aligned}{frac {partial E}{partial W_{1}}}&=left(left((Y-T)^{mathrm {T} }W_{2}right)^{mathrm {T} }circ psi '(W_{1}X+B_{1})right)X^{mathrm {T} }\{frac {partial E}{partial B_{1}}}&=left((Y-T)^{mathrm {T} }W_{2}right)^{mathrm {T} }circ psi '(W_{1}X+B_{1})\{frac {partial E}{partial W_{2}}}&=(Y-T)psi (W_{1}X+B_{1})^{mathrm {T} }\{frac {partial E}{partial B_{2}}}&=Y-Tend{aligned}}}

Python 3.5 によるソースコード。Python において、@ は行列の乗法の演算子、** は冪乗の演算子、行列同士の * はアダマール積。
import numpy as np
dim_in = 1 # 入力は1次元
dim_out = 1 # 出力は1次元
hidden_count = 1024 # 隠れ層のノードは1024個
learn_rate = 0.005 # 学習率
# 訓練データは x は -1~1、y は 2 * x ** 2 - 1
train_count = 64 # 訓練データ数
train_x = np.arange(-1, 1, 2 / train_count).reshape((train_count, dim_in))
train_y = np.array([2 * x ** 2 - 1 for x in train_x]).reshape((train_count, dim_out))
# 重みパラメータ。-0.5 〜 0.5 でランダムに初期化。この行列の値を学習する。
w1 = np.random.rand(hidden_count, dim_in) - 0.5
w2 = np.random.rand(dim_out, hidden_count) - 0.5
b1 = np.random.rand(hidden_count) - 0.5
b2 = np.random.rand(dim_out) - 0.5
# 活性化関数は ReLU
def activation(x):
return np.maximum(0, x)
# 活性化関数の微分
def activation_dash(x):
return (np.sign(x) + 1) / 2
# 順方向。学習結果の利用。
def forward(x):
return w2 @ activation(w1 @ x + b1) + b2
# 逆方向。学習
def backward(x, diff):
global w1, w2, b1, b2
v1 = (diff @ w2) * activation_dash(w1 @ x + b1)
v2 = activation(w1 @ x + b1)
w1 -= learn_rate * np.outer(v1, x) # outerは直積
b1 -= learn_rate * v1
w2 -= learn_rate * np.outer(diff, v2)
b2 -= learn_rate * diff
# メイン処理
idxes = np.arange(train_count) # idxes は 0~63
for epoc in range(1000): # 1000エポック
np.random.shuffle(idxes) # 確率的勾配降下法のため、エポックごとにランダムにシャッフルする
error = 0 # 二乗和誤差
for idx in idxes:
y = forward(train_x[idx]) # 順方向で x から y を計算する
diff = y - train_y[idx] # 訓練データとの誤差
error += diff ** 2 # 二乗和誤差に蓄積
backward(train_x[idx], diff) # 誤差を学習
print(error.sum()) # エポックごとに二乗和誤差を出力。徐々に減衰して0に近づく。
脚注
^ Homma, Toshiteru; Les Atlas; Robert Marks II (1988年). “An Artificial Neural Network for Spatio-Temporal Bipolar Patters: Application to Phoneme Classification”. Advances in Neural Information Processing Systems 1: 31–40. http://papers.nips.cc/paper/20-an-artificial-neural-network-for-spatio-temporal-bipolar-patterns-application-to-phoneme-classification.pdf.
^ Yann Le Cun (1989年6月). Generalization and Network Design Strategies. http://yann.lecun.com/exdb/publis/pdf/lecun-89.pdf.
^ Y. LeCun; B. Boser; J. S. Denker; D. Henderson; R. E. Howard; W. Hubbard; L. D. Jackel (1989年). “Backpropagation applied to handwritten zip code recognition”. Neural Computation 1 (4): 541-551.
^ Reducing the Dimensionality of Data with Neural Networks
^ A fast learning algorithm for deep belief nets
^ Neuromorphic Processing : A New Frontier in Scaling Computer Architecture Qualcomm 2014年
^ Qualcomm’s cognitive compute processors are coming to Snapdragon 820 ExtremeTech 2015年3月2日
- ^ abc複素ニューラルネットワーク
^ 複素逆誤差伝播学習アルゴリズム(複素BP)を使用した場合
^ Akira Hirose, Shotaro Yoshida (2012年). “Generalization Characteristics of Complex-valued Feedforward Neural Networks in Relation to Signal Coherence”. IEEE TNNLS 23 (4): 541-551.
参考文献
- 斎藤康毅 『ゼロから作るDeep Learning - Pythonで学ぶディープラーニングの理論と実装』 オライリージャパン、2016年9月24日、第1刷。ISBN 978-4873117584。
関連項目
- 人工知能
- 強化学習
- 機械学習
- ニューロコンピュータ
- コネクショニズム
- 認知科学
- 脳科学
- 計算論的神経科学
- ウォーレン・マカロック
- ウォルター・ピッツ
- ヘッブの法則
- 認知アーキテクチャ
- 階層構造
- 創発
- Neuroevolution
- コネクトーム
- ディープラーニング
外部リンク
ニューラルネットワーク - 菅沼研究室


